Table Extraction from Text PDF
goals
Given scientific text PDFs, find and extract tabular data exactly how you see it.
challenges
- Variation in types of tables
- Data extraction from borderless tables
- Availability of annotated data
- Evaluation metric
solution

Solution: The problem was divided into three parts:
-Table Detection
-Table Classification
-Data Extraction
-We used a Masked RCNN based approach for Table Detection
-Tables were classified based on borders
-Simple CV techniques were used to extract data from the tables with borders
-In the borderless tables, we used a signal processing technique along with CV to specify arbitrary borders
results
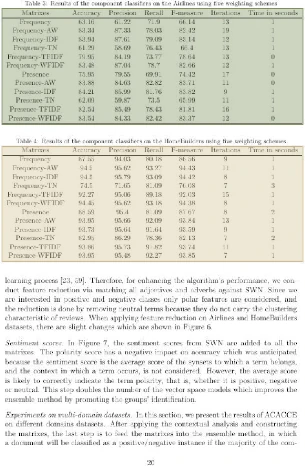
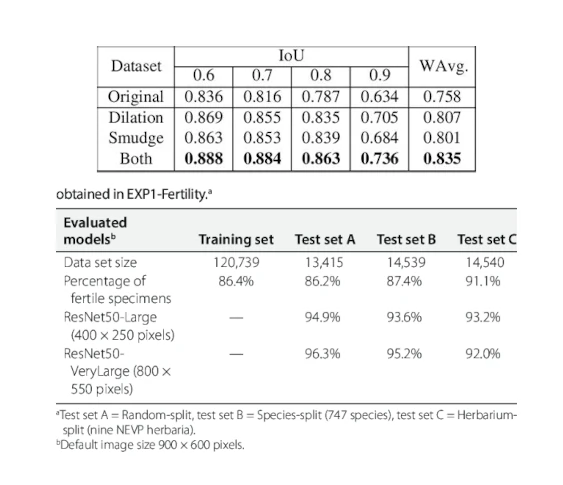
Successfully extracted bordered and borderless tables from scientific papers with over 80% accuracy with an exception of a few row-spanning and column spanning tables.